Enum DataReadingStrategy
- java.lang.Object
-
- java.lang.Enum<DataReadingStrategy>
-
- uk.ac.rdg.resc.edal.dataset.DataReadingStrategy
-
- All Implemented Interfaces:
Serializable,Comparable<DataReadingStrategy>
public enum DataReadingStrategy extends Enum<DataReadingStrategy>
Defines different strategies for reading data from files. The grid below represents the source data. Black grid squares represent data points that must be read from the source data and will be used to generate the final output (e.g. image):
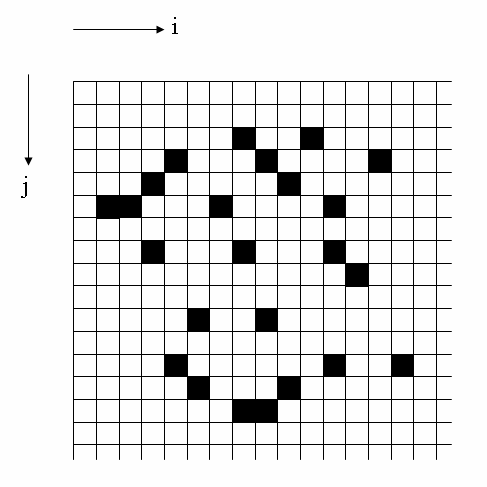
A variety of strategies are possible for reading these data points:
Strategy 1: read data points one at a time
Read each data point individually by using
DomainMapper.iterator()to iterate over allDomainMapper.DomainMapperEntrys and reading the appropriate indices fromDomainMapper.DomainMapperEntry.getTargetIndices(). This minimizes the memory footprint as the minimum amount of data is read from disk. However, in general this method is inefficient as it maximizes the overhead of the low-level data extraction code by making a large number of small data extractions. This is thepixel-by-pixelstrategy.Strategy 2: read all data points in one operation
Read all data in one operation (potentially including lots of data points that are not needed) by finding the overall i-j bounding box with
DomainMapper.getMinIIndex(),DomainMapper.getMaxIIndex(),DomainMapper.getMinJIndex()andDomainMapper.getMaxJIndex(). This minimizes the number of calls to low-level data extraction code, but may result in a large memory footprint. TheDataReaderwould then subset this data array in-memory. This is thebounding-boxstrategy. This approach is recommended for remote datasets (e.g. on an OPeNDAP server) and compressed datasets as it minimizes the overhead associated with the individual data-reading operations.This approach is illustrated in the diagram below. Grey squares represent data points that are read into memory but are discarded because they do not form part of the final image:
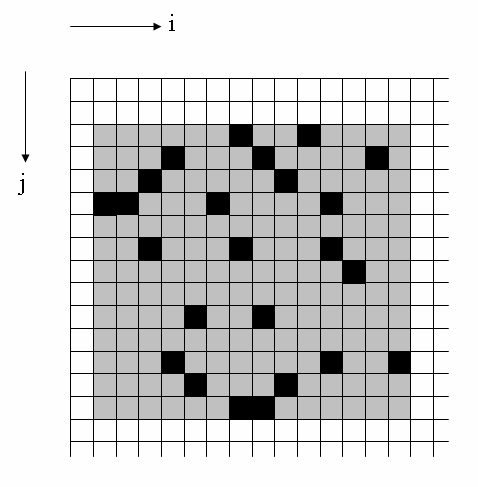
Strategy 3: Read "scanlines" of data
A compromise strategy, which balances memory considerations against the overhead of the low-level data extraction code, works as follows:
- Iterate through each row (i.e. each j index) using the
DomainMapper.scanlineIterator()andDomainMapper.Scanline.getSourceGridJIndex(). - For each j index, extract data from the minimum to the maximum i index in
this row (a "scanline") using
DomainMapper.DomainMapperEntry.getSourceGridIIndex()for the first and last entries in the row, since entries are sorted by i-index (This assumes that the data are stored with the i dimension varying fastest, meaning that the scanline represents contiguous data in the source files.)
scanlinestrategy.This approach is illustrated in the diagram below. There is now a much smaller amount of "wasted data" (i.e. grey squares) than in Strategy 2, and there are much fewer individual read operations than in Strategy 1.
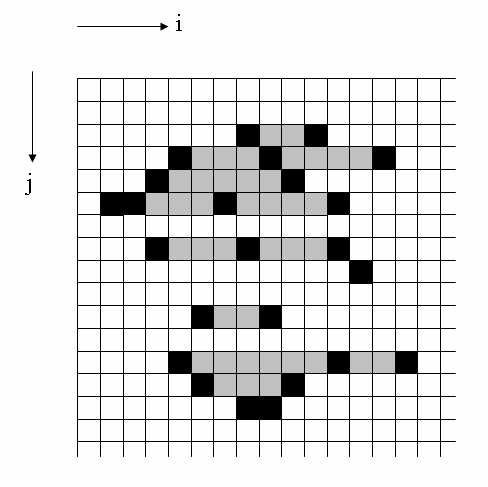
- Author:
- Jon, Guy Griffiths
-
-
Enum Constant Summary
Enum Constants Enum Constant Description BOUNDING_BOXReads all data in a single operation, then subsets in memory.PIXEL_BY_PIXELReads each data point individually.SCANLINEReads "scanlines" of data, leading to a smaller memory footprint than thebounding-boxstrategy, but a larger number of individual data-reading operations.
-
Method Summary
All Methods Static Methods Instance Methods Abstract Methods Concrete Methods Modifier and Type Method Description abstract Array2D<Number>readMapData(GridDataSource dataSource, String varId, int tIndex, int zIndex, Domain2DMapper domainMapper)static DataReadingStrategyvalueOf(String name)Returns the enum constant of this type with the specified name.static DataReadingStrategy[]values()Returns an array containing the constants of this enum type, in the order they are declared.
-
-
-
Enum Constant Detail
-
SCANLINE
public static final DataReadingStrategy SCANLINE
Reads "scanlines" of data, leading to a smaller memory footprint than thebounding-boxstrategy, but a larger number of individual data-reading operations. Recommended for use when the overhead of a data-reading operation is low, e.g. for local, uncompressed files.
-
BOUNDING_BOX
public static final DataReadingStrategy BOUNDING_BOX
Reads all data in a single operation, then subsets in memory. Recommended in situations in which individual data reads have a high overhead, e.g. when reading from OPeNDAP datasets or compressed files.
-
PIXEL_BY_PIXEL
public static final DataReadingStrategy PIXEL_BY_PIXEL
Reads each data point individually. Only efficient if the overhead of reading a single point is not large.
-
-
Method Detail
-
values
public static DataReadingStrategy[] values()
Returns an array containing the constants of this enum type, in the order they are declared. This method may be used to iterate over the constants as follows:for (DataReadingStrategy c : DataReadingStrategy.values()) System.out.println(c);
- Returns:
- an array containing the constants of this enum type, in the order they are declared
-
valueOf
public static DataReadingStrategy valueOf(String name)
Returns the enum constant of this type with the specified name. The string must match exactly an identifier used to declare an enum constant in this type. (Extraneous whitespace characters are not permitted.)- Parameters:
name- the name of the enum constant to be returned.- Returns:
- the enum constant with the specified name
- Throws:
IllegalArgumentException- if this enum type has no constant with the specified nameNullPointerException- if the argument is null
-
readMapData
public abstract Array2D<Number> readMapData(GridDataSource dataSource, String varId, int tIndex, int zIndex, Domain2DMapper domainMapper) throws IOException, DataReadingException
- Throws:
IOExceptionDataReadingException
-
-